Recently I have been developing a low-code application with Microsoft Platform, chosen SharePoint List as my data support. However, when I share the App to other users, the App will raise a pop-up window requesting the permission for accessing SharePoint List.
Install PowerShell Module
Open PowerShell with administrator right and execute the command below to install module required:
1 | Install-Module -Name Microsoft.PowerApps.Administration.PowerShell |
Acquire the Environment ID and App ID
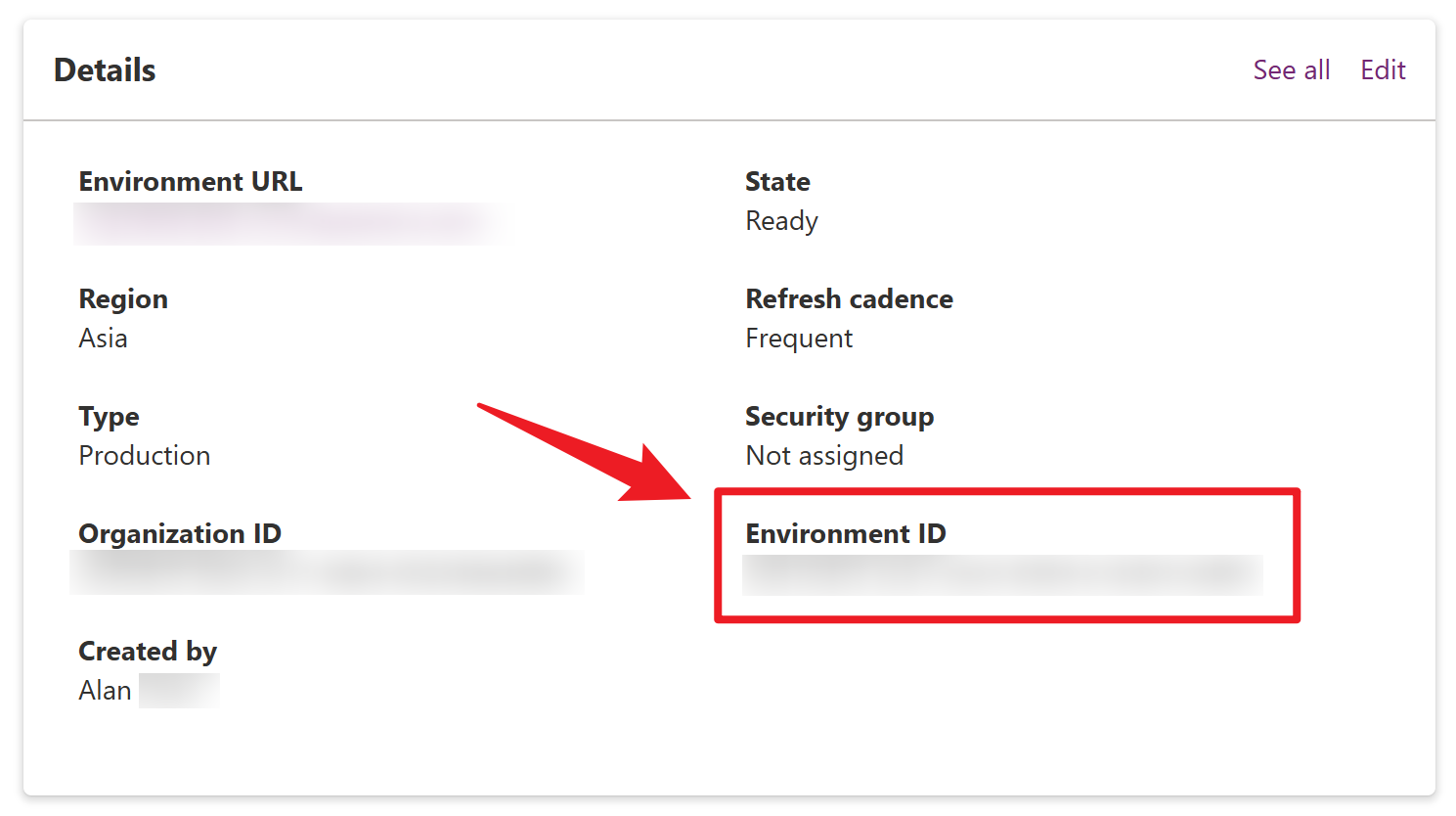
Login Power Platform admin center with your organization’s account, and find the Environment ID of the app deployed. Then, find the App ID from the detail view of the app.
Set Bypass the Consent
Finally, run the command below to set bypass the consent:
1 | Set-AdminPowerAppApisToBypassConsent -EnvironmentName 00aa00aa-bb11-cc22-dd33-44ee44ee44ee -AppName 00001111-aaaa-2222-bbbb-3333cccc4444 |
Now user will not receive the pop-up window requesting for data connection approval.
References
Programmability and Extensibility - PowerShell - Installation - Power Platform | Microsoft Learn